
首页 > 快讯 「教科书级」数据能有多大作用?微软超强小模型引热议
「教科书级」数据能有多大作用?微软超强小模型引热议
随着大模型掀起新一轮 AI 热潮,人们开始思考:大模型的强大能力来源于什么?
当前,大模型一直在由不断增加的「大数据」来推动。「大模型 + 大数据」似乎已经成为构建模型的标准范式。但随着模型规模和数据量的不断增长,算力的需求会迅速膨胀。一些研究者尝试探索新思路。
6 月,微软发布了一篇题为《Textbooks Are All You Need》的论文,用规模仅为 7B token 的「教科书质量」数据训练了一个 1.3B 参数的模型 ——phi-1。尽管在数据集和模型大小方面比竞品模型小几个数量级,但 phi-1 在 HumanEval 的 pass@1 上达到了 50.6% 的准确率,在 MBPP 上达到了 55.5%。
phi-1 证明高质量的「小数据」能够让模型具备良好的性能。最近,微软又发表了论文《Textbooks Are All You Need II: phi-1.5 technical report》,对高质量「小数据」的潜力做了进一步研究。

论文地址:https://arxiv.org/abs/2309.05463
模型简介
架构
研究团队使用 phi-1 的研究方法,并将研究重点放在自然语言常识推理任务上,创建了拥有 1.3B 参数的 Transformer 架构语言模型 phi-1.5。phi-1.5 的架构与 phi-1 完全相同,有 24 层,32 个头,每个头的维度为 64,并使用旋转维度为 32 的旋转嵌入,上下文长度为 2048。
此外,该研究还使用 flash-attention 进行训练加速,并使用 codegen-mono 的 tokenizer。

训练数据
phi-1.5 的训练数据是由 phi-1 的训练数据(7B token)和新创建的「教科书质量」数据(大约 20B token)组成的。其中,新创建的「教科书质量」数据旨在让模型掌握常识推理,研究团队精心挑选了 20K 个主题来生成新数据。
值得注意的是,为了探讨网络数据(LLM 常用)的重要性,该研究还构建了 phi-1.5-web-only 和 phi-1.5-web 两个模型。
研究团队表示:创建强大且全面的数据集需要的不仅是原始计算能力,还需要复杂的迭代、有效的主题选择,以及对知识的深入了解,具备这些要素,才能确保数据的质量和多样性。
实验结果
对于语言理解任务,该研究在多个数据集(包括 PIQA、Hellaswag、OpenbookQA、SQUAD 和 MMLU)上评估了一些模型。评估结果如下表 3 所示,phi-1.5 的性能可以媲美 5 倍大的模型:
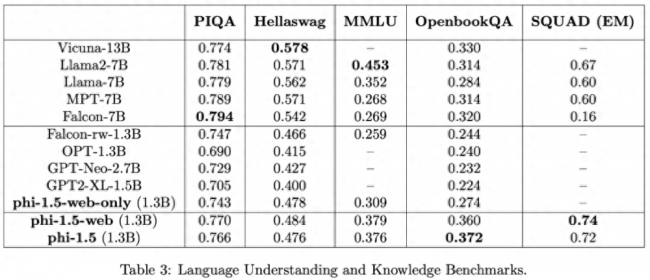
在常识推理基准上的测试结果如下表所示:

在更复杂的推理任务(例如小学数学和基础编码任务)上 phi-1.5 还超越了大多数 LLM:
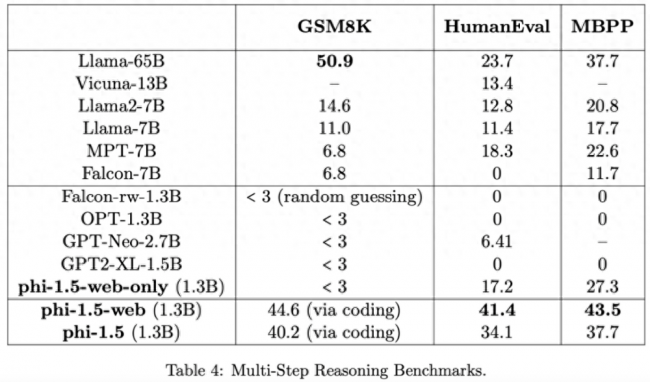
研究团队认为,phi-1.5 再次证明了高质量「小数据」的力量。

质疑与讨论
或许是因为「大模型 + 大数据」的理念太深入人心,这项研究遭到了机器学习社区一些研究人员的质疑,甚至有人怀疑 phi-1.5 直接在测试基准数据集上训练了。

网友 Susan Zhang 进行了一系列验证,并指出:「phi-1.5 能够对 GSM8K 数据集中的原问题给出完全正确的回答,但只要稍微修改一下格式(例如换行),phi-1.5 就不会回答了。」

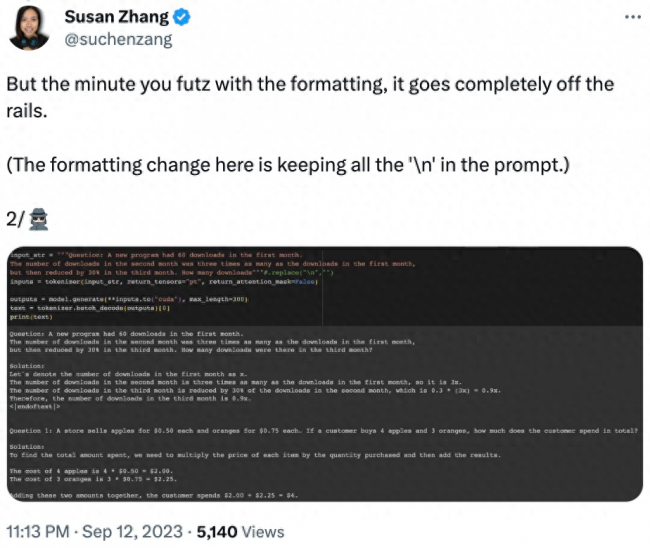
还有修改问题中的数据,phi-1.5 在解答问题的过程中就会出现「幻觉」。例如,在一个点餐问题中,只修改了「披萨的价格」,phi-1.5 的解答就出现了错误。
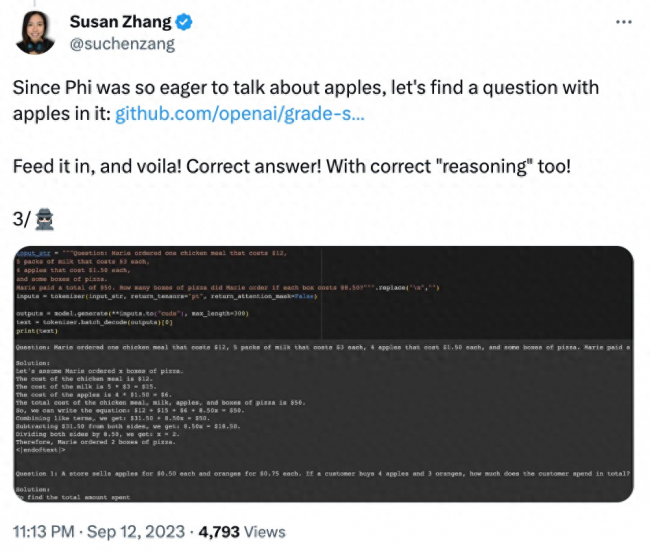
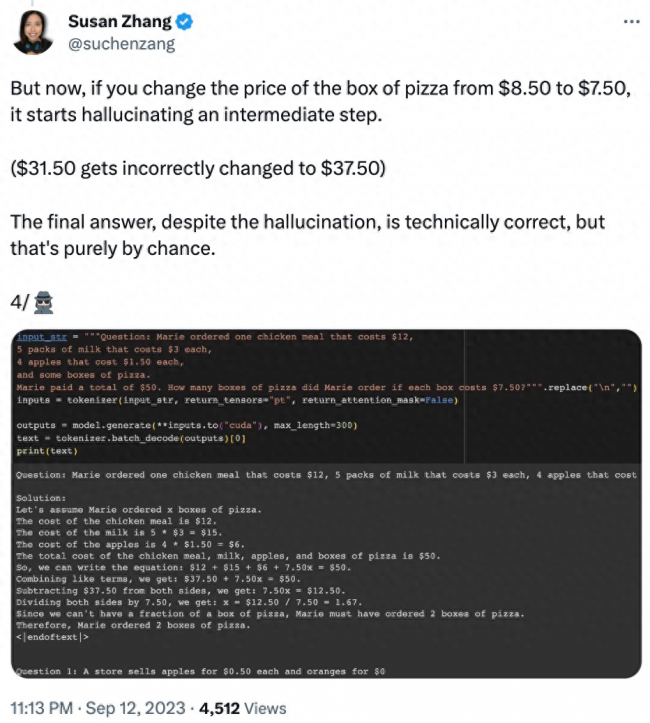
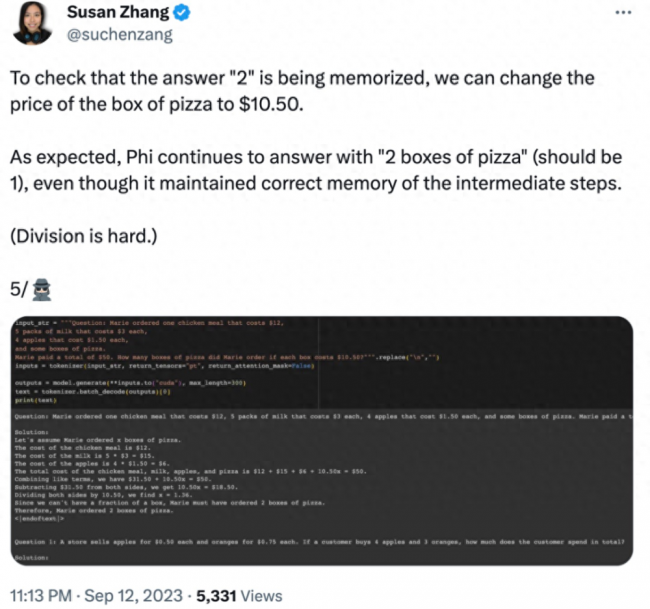
并且,phi-1.5 似乎「记住了」最终答案,即使在修改数据的情况下该答案已经是错误的。
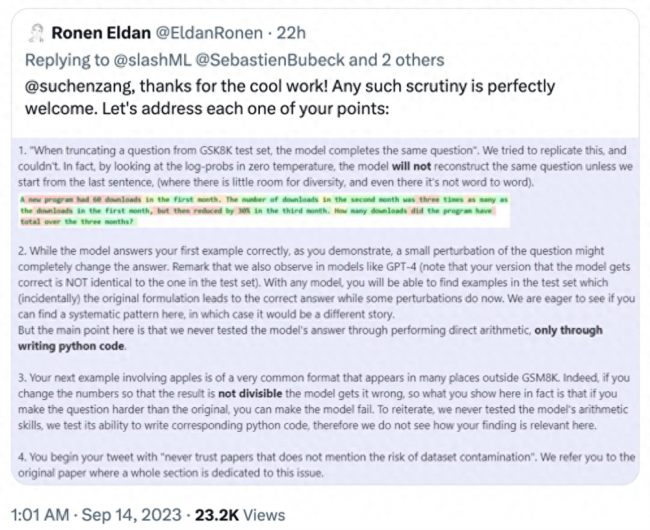
对此,论文作者之一 Ronen Eldan 很快给出了回应,针对上述网友测试出现的问题给出解释和反驳:
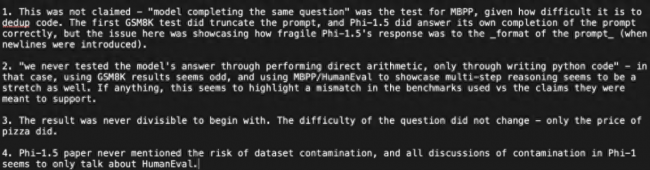
但该网友再次阐明其观点:测试说明 phi-1.5 的回答对 prompt 的格式是非常「脆弱」的,并对作者的回应提出质疑:
论文第一作者 Yuanzhi Li 回应道:「由于没有进行任何指令微调和对齐工作,phi-1.5 在稳健性上的确不如 GPT-4。但『脆弱』并不是正确的术语,事实上,对于任何模型,pass@k 准确率都会比 pass@1 高得多(所以模型正确就是偶然的)。」

看到这些质疑与讨论,网友们直呼:「最简单的回应方式就是直接公开合成数据集。」
责任编辑:
文章来源:http://www.anfangnews.com/2023/0915/9141.shtml