
首页 > 快讯 为什么大模型在当下集中爆发?
为什么大模型在当下集中爆发?
自3月以来,国内大模型进入“井喷”状态,从互联网巨头到IT企业,从科研机构到科创企业,大家对AI大模型都趋之若鹜,短时间内纷纷推出自有的大模型产品。
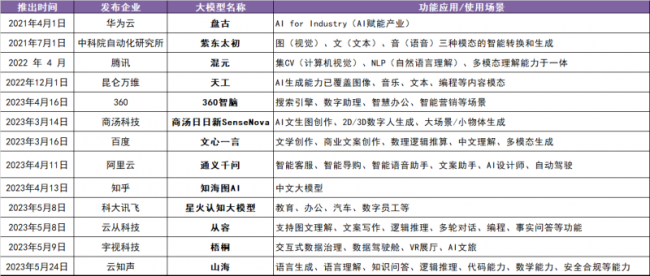
▲a&s统计的部分大模型发布情况
根据科技部新一代人工智能发展研究中心5月底发布的《中国人工智能大模型地图研究报告》显示,我国10亿参数规模以上的大模型已发布79个,几乎进入“百模大战”。
进入到四五月,大模型产品甚至以每日一款的速度扎堆诞生,一些AI、物联网企业还有科技大佬个人在各自的领域开始了新一轮的“跑马圈地”,从功能应用、适用场景以及核心技术优势等方面宣告其大模型的特色和亮点。
为什么大模型会在这个时间节点集中爆发?
ChatGPT的发布像一根引线,一经点燃,便燃起了大模型的熊熊之火,一时之间,玩家纷纷入场,各类大模型疯狂涌现。
为什么大模型会在这个时间节点爆发?

海量参数规模条件催促大模型“涌现”
从纯技术理论的角度看,中国科学院院士陈润生表示,一个复杂系统由很多微小个体构成,这些微小个体凑到一起,相互作用,当数量足够多时,在宏观层面上展现出微观个体无法解释的特殊现象,即为“涌现”。大模型的运算表明,当训练数据很大时(比如超过了1000亿),就会出现“涌现”现象。
据目前市场已公布的大模型产品来看,10亿参数规模以上的大模型产品已多达80个,其中像百度、腾讯、华为云等企业推出的大模型参数规模均已达千亿已上。
当参数规模达到一定量级的时候,大模型的涌现“现象”便具备了先决条件,这也是当下大模型爆发的一大关键。
以技术驱动变革的产业有着它自己的发展路径,中国电子信息产业发展研究院未来产业研究中心研究员、高级咨询师钟新龙同样认为,由于经过这么多年的积累,特别是信息化数字化的长达10年至20年如此长的时间积累,所以我们相比历史上任何一个时期,都有更多的数据可以用,这是训练大模型成为可能的必备要素。大模型即便放到历史维度中提前的某一个时刻,可能因为数据不够,训练的效果会不太好。
企业间的竞争角逐
大模型的爆发,还跟企业间的竞争意识相关联。
目前已推出大模型产品的企业,无一例外是通用或垂直行业领域头部玩家,这些玩家之间不排除很多企业存在“竞争”心理,人无我有,人有我优的心态也驱动着大厂在大模型赛道你追我赶,推陈出新。
在人工智能领域,几乎所有的研究团队,包括头部企业都在竞争开发最先进的大模型,而且不少头部大模型都开始走向开源开放。这种竞争是一种良性的竞争,它有利于推动技术的发展,也有利于推动技术的共享。
产业认知达成新的共识
底层技术,包括数据、算力、算法的支撑为大模型奠定了必要的条件和基础,而国内大模型在今年开始爆发,还有一大原因在于大家对于AI大模型的应用需求达到新的峰值。无论是用户端还是技术供应端,大家普遍看到了AI技术应用的需求和困境,此前的AI工具普遍存在泛化能力不足,使用成本高企等问题,亟待通用性强、泛化能力强、能够便捷使用的新的AI工具,AI大模型是数字经济驱动下产业认知达成共识的产物。
目前市场上已发布的大模型普遍具备大规模和预训练的特点,一方面有良好的通用性、泛化性,能够解决传统AI应用中门槛高、部署难的问题,另一方面可以作为技术底座,支撑智能化产品及应用落地。
360创始人周鸿祎表示,互联网公司都去做大模型的原因,是因为没人能笃定某一家公司能做出来成功的大模型产品。但这个技术对中国很重要,它是工业级的,对各行各业都能带来工业革命级的推动。
用大语言模型来变革业务层、为具体的业务落地场景赋能,这也已经是诸多互联网厂商的共同策略。并且在当下这个存量市场中,在效率上的些许变化就已经能兑现为竞争优势。
大模型成为应对AI领域应用碎片化的一种方式。
大模型也正在改变AI产业的规划与格局。比方说,牵引AI产业快速收敛,构建AI产业的底座;汇聚和沉淀行业生态及开发者生态,形成产业生态黏性。
责任编辑:赵智华
文章来源:http://www.anfangnews.com/2023/0706/7865.shtml