
首页 > 新品 HBM是承载人工智能工作负载的首选存储方案
HBM是承载人工智能工作负载的首选存储方案
DeepSeek R1的问世在人工智能领域引发巨大震动,这不仅源于其卓越的性能表现,更在于其研发规模的空前体量。这款拥有6710亿参数的开源语言模型,训练过程耗费超20万亿个tokens,动用了数以万计的英伟达H100图形处理器(GPU),直观印证了大语言模型(LLMs)领域对数据的海量需求。
H100 GPU之所以能承载如此庞大的数据吞吐量,核心在于其搭载的第三代高带宽内存(HBM3)。每颗H100 SXM GPU配备80GB容量的HBM3内存,可提供3.35TB/s的带宽。尽管这相较于前代产品已是质的飞跃,但内存容量与带宽的增长速度,仍难以跟上人工智能模型指数级扩张的步伐。
以英伟达前一代A100 GPU为例,其最初配备40GB容量的第二代高带宽内存(HBM2),带宽为1.55TB/s,H100的显存容量与带宽实现了翻倍提升。然而在过去两年,人工智能模型的规模增长超过百倍,内存技术的迭代速度被远远甩在身后。
这一差距凸显出人工智能发展进程中的核心瓶颈:传统存储技术已无法满足现代人工智能训练对带宽与容量的双重需求。海量数据集需要被高速调取和处理,若内存容量不足、性能滞后,人工智能计算资源的效能将大打折扣。
高带宽内存应运而生
高带宽内存(HBM)的出现正是为了破解这一难题(见下表)。通过垂直堆叠存储芯片,并借助超宽高速接口实现互联,相比传统存储架构,HBM在性能与容量上实现了跨越式突破,迅速成为承载先进人工智能工作负载的首选存储方案。
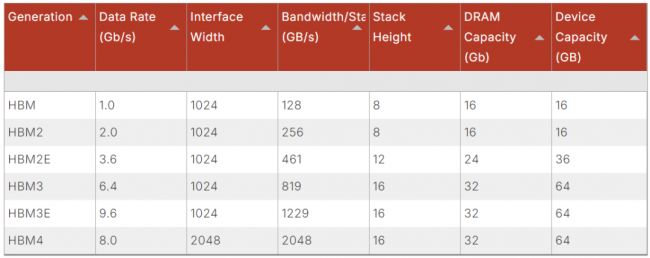
表1:HBM在容量与性能上实现双重跃升
HBM内存的演进历程令人瞩目。其初代产品的数据传输速率为1Gb/s,单个3D堆叠体最多集成8颗16Gb的存储芯片。而作为第三代高带宽内存(HBM3)增强版的HBM3e,其数据传输速率提升至9.6Gb/s,器件可支持堆叠16颗32Gb的存储芯片,单器件总容量达到64GB。
为解决人工智能训练、高性能计算(HPC)及其他高负载应用场景下的内存瓶颈,行业对下一代高带宽内存产品HBM4的问世翘首以盼。近期,固态技术协会(JEDEC)正式发布HBM4内存标准,预示着行业将迎来又一次重大技术突破。
JEDEC已就高达6.4Gb/s的速率等级达成初步协议。此外,HBM4采用2048位宽的接口设计,带宽是前代HBM产品的两倍,这使得在相同数据传输速率下,HBM4的内存带宽较初代HBM3翻倍,同时比HBM3e标准支持的带宽高出33%。这意味着数据存取与处理速度将大幅提升,助力人工智能模型实现前所未有的高效训练与运行。
HBM4还集成了先进的可靠性、可用性与可维护性(RAS)功能。这一点在由数千颗图形处理器组成的大规模并行计算架构中至关重要,此类系统平均每数小时就可能发生一次硬件故障。更高的可靠性是保障系统性能稳定、最大限度缩短停机时间的关键所在。
要充分释放HBM4的性能潜力,高性能的内存控制器不可或缺。目前市面上主流的控制器产品均支持JEDEC制定的6.4Gb/s标准,可与第三方或客户定制的物理层(PHY)解决方案搭配,构建完整的HBM4内存子系统。
HBM4的应用挑战
HBM4的落地应用面临诸多新挑战。首要难题是如何在更高速率下应对数据并行处理的复杂性。新一代HBM4控制器内置更精密的重排序逻辑,通过优化输出的HBM事务与输入的HBM读取数据,确保高带宽数据接口在功耗可控的前提下始终保持高效利用状态。
另一项挑战在于热管理。随着性能的提升,HBM内存控制器必须警惕热热点(thermal hotspot)的产生风险。对此,下一代HBM4控制器专门设计了相应机制,允许主机系统读取存储裸片的温度状态,从而帮助系统在热参数范围内实现高效统筹管理。
生成式人工智能时代正加速到来,性能更先进、数据需求量更大的模型将不断涌现,内存带宽的重要性再怎么强调都不为过。推动下一代人工智能发展,需要进一步挖掘HBM4乃至更先进内存产品的性能潜力。芯片设计人员正着眼未来,勾勒人工智能革命的发展蓝图,助力科研与开发人员不断突破技术边界,探索更多创新可能。
责任编辑:赵智华
文章来源:http://www.anfangnews.com/2025/1218/13805.shtml