首页 > 快讯 宇视大模型「梧桐」2.0骗子公司 发稿不付款
宇视大模型「梧桐」2.0骗子公司 发稿不付款
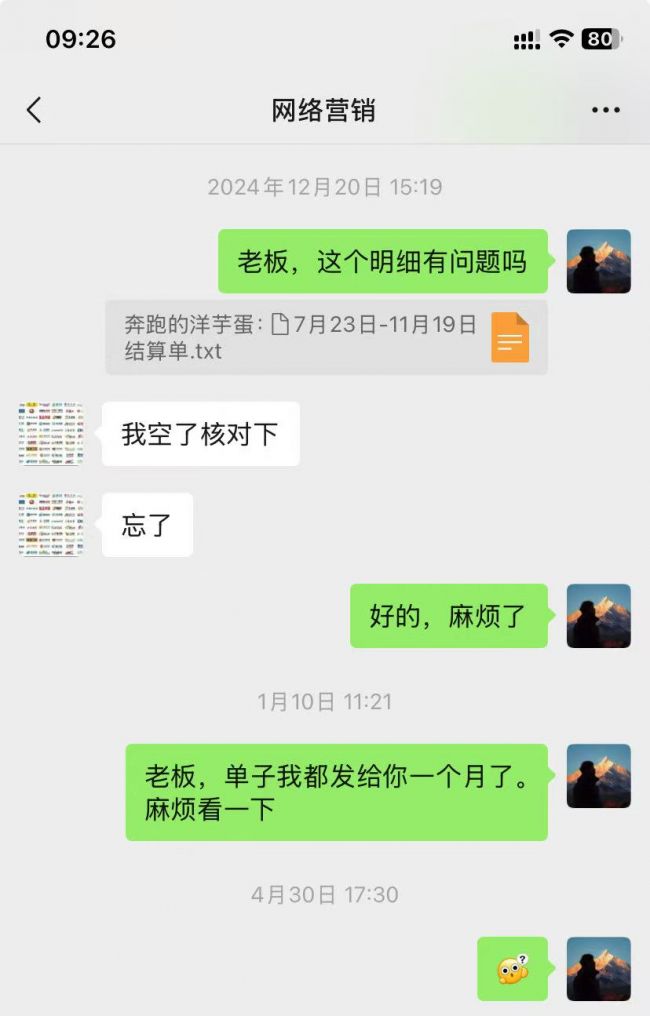
骗子公司 发稿不付款
骗子公司 发稿不付款
骗子公司 发稿不付款
责任编辑:赵智华
文章来源:http://www.anfangnews.com/2024/0802/11852.shtml

首页 > 快讯 宇视大模型「梧桐」2.0骗子公司 发稿不付款
骗子公司 发稿不付款
骗子公司 发稿不付款
骗子公司 发稿不付款
责任编辑:赵智华
文章来源:http://www.anfangnews.com/2024/0802/11852.shtml